-
专题6-5:智慧学习资源的关键开发技术
普通类 -
- 支持
- 批判
- 提问
- 解释
- 补充
- 删除
-
-
一、智慧学习资源平台体系架构
(一)智慧学习资源概念
目前对智慧学习资源的定义较少,学者郑旭东认为,智慧学习资源是指以培养具有21 世纪生存技能的智慧创造者为目的,支持智慧学习和智慧教学活动的有效开展,具有泛在性、情境感知性、联通性、进化性、多维交互性和个性化智能推送等核心特征的新型数字化学习资源。
参考学者郑旭东的定义,在学习资源的基础上,可以给出智慧学习资源的定义:智慧学习资源是一系列为学习者提供个性化学习,支持多种学习方式,与教学各环节融合,满足学生的需求,创造高效的学习环境,并支持智慧学习和智慧教学活动的有效开展的资源。
(二)智慧学习资源平台体系架构初探
一个完整的智慧学习资源平台的运转需要学习资源、存储空间、计算资源、应用系统以及操作界面[1],我们可以从应用层、管理平台层、数据层以及基础设施层几个方面考虑。
为满足学生的需求,对于智慧学习资源平台体系的设计如图1所示:

图1 智慧学习资源平台体系架构
1.用户
智慧学习资源平台的用户可以分为五种类型:学生,教师、系统管理员、家长以及公众。登录这个平台,学生可以在线学习课程,下载课件、习题等学习资料,自我测验,或者通过论坛和老师或者同学交流学习中遇到的问题等。教师们通过智慧学习资源平台指导学生学习课程,在线布置作业并和学生进行在线交流等。系统管理员则负责学习平台中用户信息管理,课程信息管理,论坛管理等相关工作。家长可以在平台上查看学生的学习状况,并与教师及时沟通,帮助学生进一步提高。公众是指社会公众,智慧学习资源平台可以为社会上的人提供其需要的智慧学习资源。
2.客户端
随着通信网络技术以及无线移动通信设备的不断发展,这里所提的客户端不仅仅指个人计算机,还包括智能手机、等移动支持设备。客户端是用户与系统交互的媒介,负责把系统内容呈现给用户,系统会根据用户持有的设备类型提供不同的界面和功能。
3. 应用层
在整个智慧学习资源平台的体系架构中,应用层用来提供各类与教育教学有关的应用软件,即提供面向教育的。该层主要包含一个在线学习网络平台,此网络平台是整个系统的支架,不承载具体数据内容。但是用户登录此网站首页进入该平台,就可以通过接口调用智慧学习资源平台提供的相关服务。
4. 管理平台层
管理平台层在整个智慧学习资源平台的体系结构中起着核心的作用,为应用层的在线学习系统提供运行环境,是面向教育的各种应用软件的应用平台。
5. 数据层
数据层是整个架构的核心层,它负责各种类型的数据存储。对智慧学习资源平台而言,学习资源的建设是在线学习的核心和基础。在如今各个在线学习平台各自为政的环境下,学习资源难以得到充分利用,通过云计算的数据存储服务将资源整合构建一个公共统一的资源池供用户分享是解决这个问题的着眼点[2]。
6. 基础设施层
基础设施层是整个架构的基础层。基础架构层向用户提供服务器、存储空间、网络设备等硬件资源,只不过这些硬件资源并不只是真正的物理设备,而是通过虚拟化技术使得服务器虚拟化、存储虚拟化以及网络虚拟化。
-
二、智慧学习资源的语义化组织技术
(一)相关概念
语义网络的概念最早由Collins和Guilian提出,它是一种用来表达概念间相互关系,揭示深层语义信息的知识组织系统。一个语义网络是某个领域知识或概念之间关系的网式图,一般由节点和有向链或有向弧构成。
本体作为语义网中的核心技术,是实现语义网中语义操作的基础。关于本体的定义较多,较为认同的是R.Studer的解释:“本体是对概念体系的明确的、形式化的、可共享的规范说明”,是一种能在语义和知识层次上描述信息系统的概念模型的建模工具,能够有效表现概念层次结构和语义。
为了实现学习资源语义特征的自动提取来解决学习资源语义化改造的问题,杨现民与余胜泉教授提出了“语义基因”的概念。语义基因是用来描述资源的语义特征,是一种基于本体的资源语义表示方式[4]。
(二)案例分析——MOOC 平台下课程资源的语义化组织模型[3]
该MOOC名称:数据库原理与应用
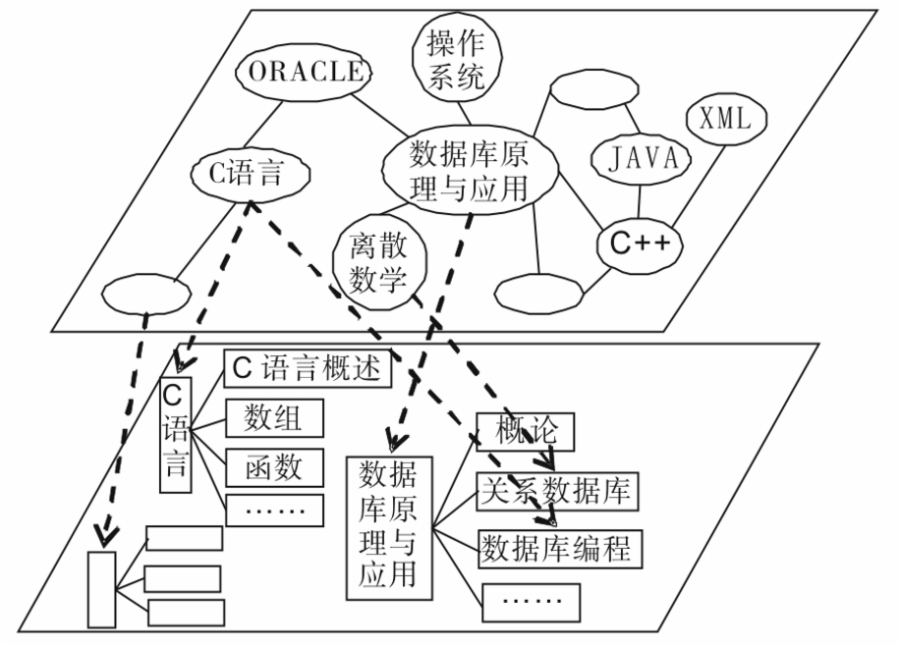
图1 MOOC 平台下课程资源的语义化组织模型
如图1所示,MOOC 平台下课程资源的语义化组织模型分为上层的课程语义描述层和下层的学习对象包装层。其中课程语义描述层是指:通过应用本体描述、语义基因等技术来清晰地表述出MOOC平台中课程的特征以及课程之间的语义关系,使得课程不再是散落分布,最终形成一个通过各种关系关联起来的语义网络。学习对象包装层是指:对于单个课程内部的教学资源,可以用传统的树状结构组织起来,并且利用学习对象与内容包装等技术实现共享与复用。
1.课程语义描述层
语义描述层主要功能是描述课程的基本特征以及课程之间的关系,具体步骤包含:
(1)课程基本信息描述
(2)课程领域本体库的构建
a.确定本体的领域和范围
b.列举领域中的重要概念术语
c.定义类(概念)以及类(概念)层次,如图2所示
d.属性定义(用 OWL/RDF 语言表示),如图3所示
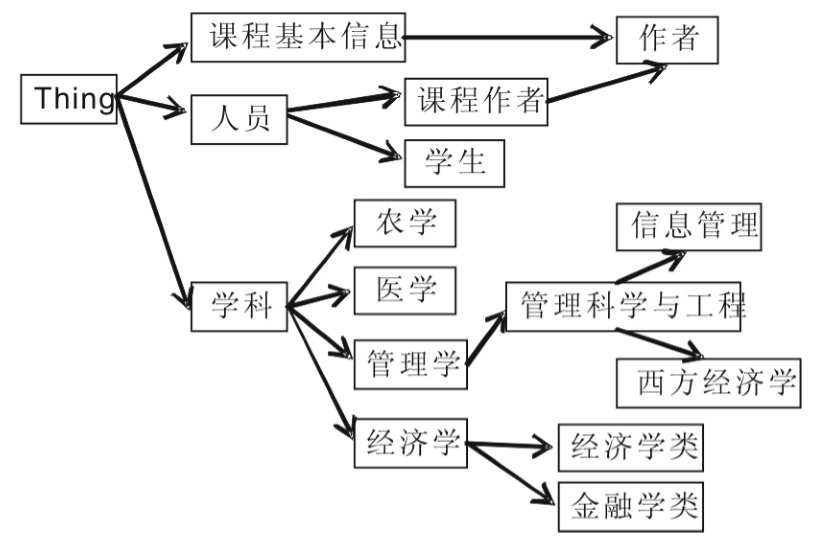
图2 课程领域概念层次图

图3 课程本体语言描述
(3)基于生成性信息以及本体库的课程资源特征描述,如图4所示
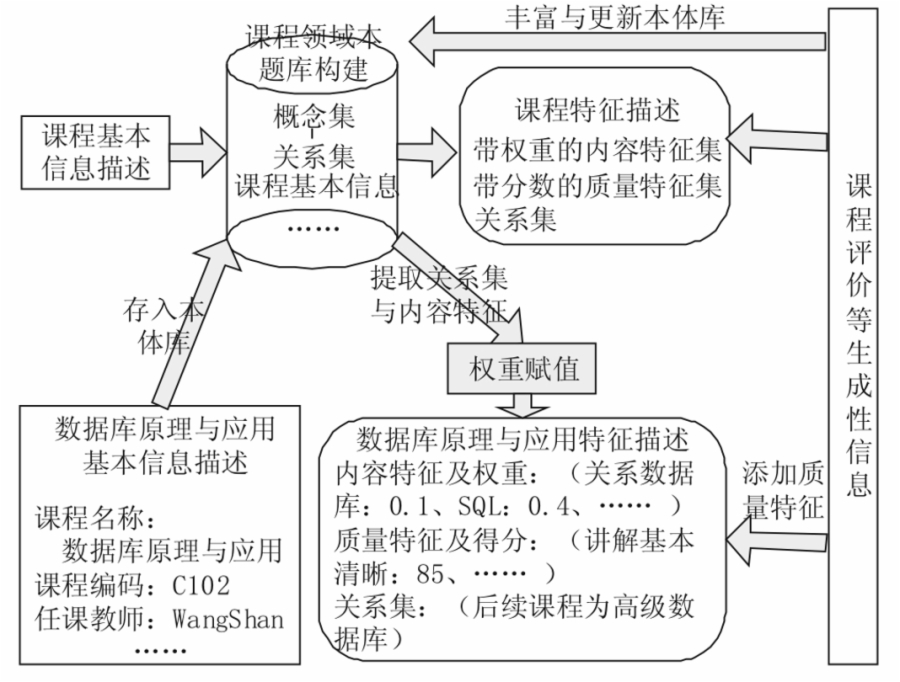
图4 课程特征构建过程
应用:已构建好的课程特征描述在实际的学习过程中可以起到智能推荐与个性化学习的功能。比如,“C语言程序设计”课程完成之后,系统根据“C语言程序设计”特征描述的关系集合中得出可以推荐学习数据库一类的课程。同时,平台中可能包含多门数据库课程,根据对内容特征以及权重的分析,学生可以自由选择自己更感兴趣的课程,例如感兴趣SQL语言,根据内容特征的权重推选出SQL内容特征权重较大的课程,同时可以根据课程的质量特征得分,挑选出评价。
2.学习对象包装层
(1)内容与操作绑定的学习对象包装模型(如图5所示)
此模型从内容与操作两个方面对课程资源进行组织。
内容方面在粒度维度上将学习资源划分为三个层级,从小到大依次为:元学习资源、底层学习对象、复合层学习对象。其中元学习资源是指:不能再被分割的、具体的物理文件;例如教学视频媒体、Word文件等。一个或者若干个相关元学习资源以学习目标为聚合点,按照一定的组织结构聚合起来,可以形成一个具有某个学习目标的底层学习对象;同时,一个或者若干个相关的底层学习对象以某个学习目标为聚合点,可以形成一个具有某个学习目标的复合层学习对象。
功能方面对应内容结构从下往上设计相应的操作功能,依次为:基础操作功能、高级操作功能与智能操作功能。其中基础操作可以包含上传、下载、添加、删除、编辑等,它的作用域是存在于该系统的任何学习资料和学习对象;高级操作包含导航、超链接、搜索等,它作用于多个元学习资源的聚合体上或者多个学习对象的聚合体上,为用户与学习资源之间的信息交流提供便捷的方式。智能操作包含学习地图、学习设计等定制化个性操作。

图5 内容与操作绑定的学习对象包装模型
(2) 学习对象元数据表示方案
根据上文的学习对象包装模型设计,从内容与操作两部分来制定元数据元素,如图6和图7所示。

图6学习对象内容信息表

图7 学习对象操作方面的代码
-
三、智慧学习资源动态语义关联技术
学习资源间丰富的语义关联,一方面可以增强资源个体之间的联通,提高各自被浏览或内容编辑的概率,促进资源的快速进化;另一方面还可以为学习资源动态聚合成更大粒度、具有内在逻辑联系的资源群提供数据基础。当前的数字化学习资源普遍缺乏关联性,因为资源之间的联系是通过一般的超链接形成的人为关联,基于HTML的数据组织不能体现数据内在的语义联系[1]。
鉴于此,下面介绍一种基于学习元平台(Learning Cell System, LCS)的综合应用语义基因、基于规则的推理、关联规则挖掘等技术实现资源动态语义关联的方法[3]。
一、学习资源动态语义关联技术实现
学习资源间的关联主要包括两种类型,一种是显性关联,另一种是隐性关联。显性关联是从语义出发基于系统已有的关系类型建立的资源关联,易被用户观察和识别;隐性关联是从语义上难以通过人工发现,但可以通过数据挖掘技术识别出来的潜在的资源关联。图1描述了LCS中学习资源的动态语义关联技术。在显性关联的建立上分别采用了基于规则的推理技术和基于语义基因的相似关系计算技术,在隐性关联的建立上主要采用了基于语义约束的关联规则挖掘技术[7]。
鉴于此,本文基于学习元平台(Learning Cell System, LCS),提出了一种综合应用语义基因、基于规则的推理、关联规则挖掘等技术实现资源动态语义关联的方法。
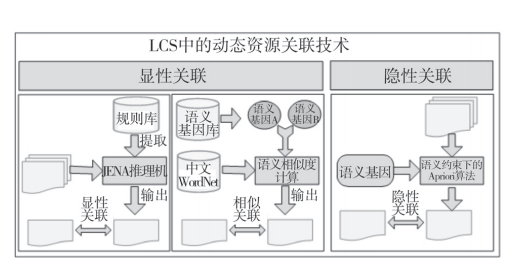
图1 LCS中学习资源的动态语义关联技术
1.基于规则推理的资源显性关联
JENA[12]是由HP Lab开发的一款用于Semantic Web应用程序开发的开源框架,除了包含丰富的本体操作API外,还支持基于产生式规则的前向推理。LCS可以应用JENA框架操作本体模型,自定义各种产生式的关联规则,通过JENA推理机实现部分资源显性关联。基于规则推理实现资源显性关联的基本流程如图2所示:

图2 基于规则推理的资源显性关联流程
2.基于语义基因的资源相似关系计算
语义基因是指能够反映资源内容所要表达含义的基本信息单元,形式上表现为基于本体描述的带有权重的概念集合以及概念间的语义关系。区别于文本相似度比较中的文档特征项,语义基因不是简单的关键词集合,而是资源背后所隐藏的语义概念网络。
基于语义基因的相似关系计算的基本思路是:首先,基于通用的语义词典和领域本体计算语义基因中两两概念间的相似度;然后,结合概念在语义基因中的权重值设置相似度的权值;接着,将所有相似度进行加权平均得到两个语义基因的相似度;最后,根据设定的相似度阈值判断两个资源是否具有相似关系(见图3)。

基于语义基因的相似关系计算的步骤为:首先将两组语义基因中的概念进行两两相似度计算;然后将所有相似值采用加权平均的方式计算得出两组基因的相似度,若结果大于或等于相似关系的阈值,则视两个资源存在相似关系,反之,则认为二者不存在相似关系。
3.基于关联规则挖掘的资源隐性关联
关联规则挖掘是数据挖掘领域非常重要的一个课题,旨在发现大量数据中项集之间有趣的关联或相关联系。关联规则挖掘技术可以很好地应用于学习资源的动态关联,通过自动挖掘一些潜在的关联规则来促进资源实体间建立更丰富的关联关系。关联规则挖掘的经典算法是Apriori算法。
LCS中订阅和收藏是两种非常重要的用户与资源间的交互,应用关联规则挖掘技术可以发现被很多用户同时订阅/收藏的资源对集,而这些资源对间极有可能存在某种联系。
为了提高关联规则挖掘的效率和准确性,对Apriori算法进行改进,除了考虑最小支持度(min_supp)、最小置信度(min_conf)外,还增加了最小语义相关度(min_semrel)指标来约束关联规则的产生,提出一种基于语义约束的关联规则挖掘算法(SC-Apriori,Semantic Constraint Apriori)。最小语义相关度是指频繁项中包含的实体之间的最小相似度,min_semrel可以通过资源的语义基因进行计算。通过min_semrel一方面可以过滤掉很多毫无意义的候选项目集,提高算法效率,另一方面,有助于产生更高质量的关联规则。
4.资源关联的可视化展现
通过动态语义关联技术可以在不同的资源结点之间建立起各种语义关系,形成不断扩展的语义关系网络。为了直观地呈现整个资源语义空间,LCS中采用Flex技术开发了如图4所示的可视化知识网络。每个结点代表一个学习元,连线表示学习元之间的语义关系。
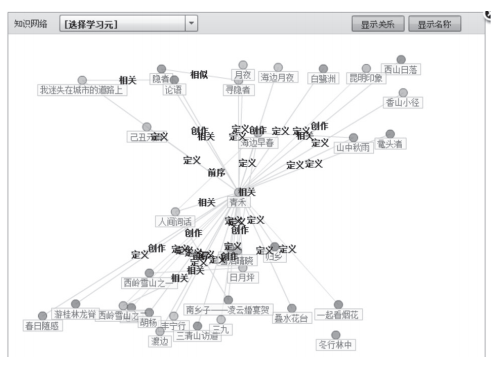
-
四、智慧学习资源的自适应呈现技术
(一)定义
自适应呈现技术:可以根据物理终端种类和特性动态调整文件格式来适应终端设备的呈现,这种自适应又称设备无关性,从广义上讲指操作系统把所有外部设备统一当作文件来看待,只要安装了相应的驱动程序,任何用户都可以像使用文件一样操纵使用这些设备,而不必知道它们的具体存在形式 [8]。
(二)应用
1.通过缩小图片、字体以及删除空白等技术将网页调整为手持设备屏幕的宽度。
2.Alexander Blekas等人提出了基于 RSS内容的自适应策略。在显示内容方面,利用RSS 的即时更新性,将最新信息呈现给学习者(需经过学习者同意)。
3.韩壮志等人提出了基于界面调整的自适应模型[9],其基本思想是通过显示程序获取终端设备的基本物理信息,根据获取到的分辨率参数进一步判断屏幕类型(横屏、竖屏)。然后通过屏幕分辨率确定缩放比例,调整控件大小,最后对文字、控件按照这个比例进行缩放以实现在终端设备的自适应显示。
4.李晶提出了设备自适应模型与设备识别 Agent(Agent 是指模拟人类行为与关系、具有一定智能并能够自主运行和提供相应服务的程序)结构 [10]。
5.李浩军等人采用 ANFIS (自适应神经模糊推理系统)方法来求解学习位置、学习需求、网络速率以及设备电量四变量值输入下的函数最优解,从而为移动学习者推荐最适合的资源呈现方式。
(三)具体案例--基于ANFIS的移动学习资源自适应呈现模型
1.内容简介
假设移动学习资源呈现方式用变量 ResourceType 来表示,学习者的学习位置、学习需求、网络速率以及设备电量四个情景因素变量分别为:Location、Need、NetworkRate、Battery,则问题可用下列函数来表示:
ResourceType =Fun(Location ,Need ,NetworkRate ,Battery ) ......公式(1)
即采用 ANFIS (自适应神经模糊推理系统)方法来求函数最优解,从而为移动学习者推荐最适合的资源呈现方式,实现移动学习效率的最大化[11]。
2.模型构建
采用 ANFIS 方法,构建一套面向移动学习资源呈现方式的自适应神经模糊推理模型,该模型是具有自学习算法的模糊神经网络系统,能产生一系列“IF…THEN”规则,并利用神经网络的自学习机制,为模糊控制器自动提取模糊规则及模糊隶属函数,使整个系统成为自适应模糊神经网络系统。
该模型通过 ANFIS 的自学习能力和模糊推理能力为移动学习者提供符合当前情景特征的资源呈现方式,以提高移动学习的学习效率,并保持移动学习者的学习兴趣。通过对学习者当前情景(学习位置、学习需求、网络速率和设备电量)的信息感知和分析进行自适应神经模糊推理,进而选择合适的资源呈现方式,为学习者高效地呈现学习内容。基于ANFIS 的移动学习资源呈现模型如图 1 所示:

-
五、智慧学习资源的个性化推荐技术
(一)定义
个性化推荐:推荐系统根据用户的个性化特征,如兴趣、爱好、职业或专业特点等,主动地向用户推送适合其学习需要或可能感兴趣的信息资源的一种推荐技术[12]。此外,个性化推荐技术可以共享用户间的经验,为目标用户推荐其相似用户群偏好的信息资源。其工作原理是:首先根据用户信息建立用户兴趣模型;然后,在信息资源库中寻找与其匹配的资源信息并产生推荐,以满足不同用户的个性化需求。
(二)分类
按实现算法和实现方式的不同,个性化推荐技术可分为基于关联规则的推荐、内容过滤推荐、协同过滤推荐等三种,也可以综合以上三种推荐方式产生新的混合型推荐算法。
1.基于关联规则的推荐
工作原理:首先由管理员定制一系列的规则条目,然后利用制定的规则度量项目间的相互关联性,将关联密切的项目推送给用户。在进行推荐时,系统分析用户当前的兴趣爱好或访问记录,然后按照事先制定的规则向用户推荐其可能感兴趣的资源项目[13]。
2.内容过滤推荐
工作原理:采用概率统计和机器学习等技术实现过滤,首先用一个用户兴趣向量表示用户的信息需求;然后对文本集内的文本进行分词、标引、词频统计加权等,生成一个文本向量;最后计算用户向量和文本向量之间的相似度,把相似度高的资源条目发送给该用户模型的注册用户。
3.协同过滤推荐
与前两种推荐技术不同,协同过滤推荐需要在分析资源内容、计算资源和用户的匹配度的基础上产生用户推荐,产生推荐的依据是用户对资源的评分。其工作原理:首先分析用户特性,如兴趣、职业等信息;然后利用相似性算法计算用户间的相似性,找出与目标用户相似性最高的k个用户;最后参照邻居对资源的评分预测目标用户对资源的评分,将预测评分最高的n个资源推荐给目标用户[14]。
(三)具体案例--协同过滤推荐的实现
协同过滤推荐系统使用统计技术搜索目标用户的若干最近邻,然后根据最近邻对项目的评分预测目标用户对项目的评分,产生对应的推荐列表。协同过滤推荐的实现流程如图2所示,具体包含三个关键步骤:获取及表示用户信息、形成邻居和产生推荐。
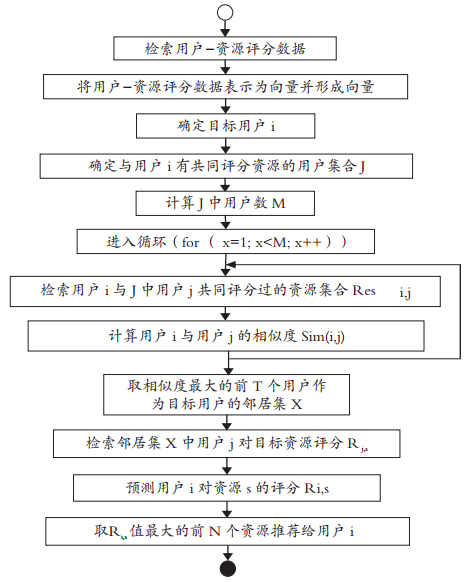
图2 协同过滤推荐算法流程图
-
六、智慧学习资源的动态聚合技术
(一)定义
智慧学习资源的动态语义聚合不是简单地将多个学习资源组成一个资源集,而是通过技术手段将多个语义上具有强逻辑关系的资源按照特定的组织方式自动聚合成资源群(资源集合),且聚合结果不是一成不变的,会随着资源之间关联关系的变化而动态更新和发展。区别于数据挖掘中的文本自动分类或聚类,聚合的目的不是为了进行分类,而是对有内在逻辑关联的资源个体间进行聚集和融合使其成为有助于促进学习的、有意义的资源结构体(如图3所示)。
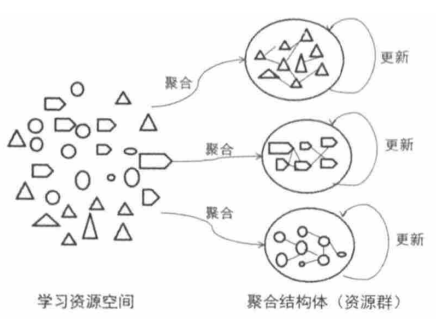
图3 智慧学习资源动态语义聚合
(二)分类
学习资源动态语义聚合有两种主要形态分别是主题资源圈和有序知识链。
1.主题资源圈
学习资源的自动聚类借鉴数据挖掘领域的聚类思想实现学习资源的自动分类形成若干个主题资源圈。比如:将所有关于就业求职的资源自动组合成“就业求职类”主题资源圈。
2.有序知识链
有序知识链是多个具有前后序关系的资源个体的聚合。链条上的知识点具有显性的前序、后继关系,也就是说,按照正常的学习流程,需要先学完前一个知识点,方可进入到下一个知识点的学习。
基于资源关联信息自动将分散的资源结点进行结构化的逻辑组合形成有序知识链,比如:可以将一元二次方程的概念、求解方法、测试试题、案例分析等资源根据“前序-后继”的语义关系自动聚合成 “一元二次方程求解教程”的知识链,学习者可以按照顺序将各个知识点集中起来系统学习一主题资源圈。
(三)技术实现
应用动态语义关联技术可以在资源空间的结点间建立起丰富的语义关系,形成资源语义关联网络。资源语义关联网络实际上是采用有向图表示的关系空间。聚合引擎从大量的关系中挖掘出更大粒度的有意义的资源结构体,依据设定的聚合规则生成主题资源圈和有序知识链两种资源聚合结构体。其实现的总体技术框架如图4所示。
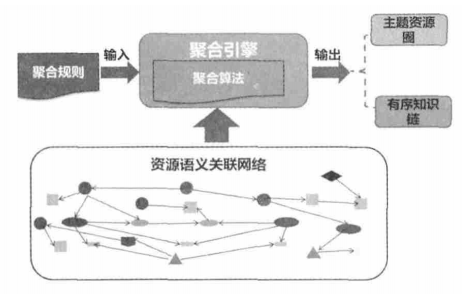
图4 动态语义聚合技术路线
-
七、智慧学习资源的智能检索技术
智能检索以文献和检索词的相关度为基础,综合考查文献的重要性等指标,对检索结果进行排序,以提供更高的检索效率。智慧学习资源的智能检索要求同时考虑信息的相关性、时效性、重要性、查全率、查准率及检索速度。[15]智能检索技术应该是从“人找信息”到“信息找人”的跨越。
(一)智能代理技术
1.定义
在信息资源检索领域里, 它是指代表用户或其他程序, 以主动服务的方式完成一定信息检索任务的操作, 并具有智能性、自主性、交互性和可移动性的计算系统。在完成操作的过程中, 智能Agent 能够主动地学习获取有关操作对象的知识及有关用户的意图和偏好的知识, 并能将这些信息在以后的检索操作中加以应用。
2.工作原理
智能Agent 一般由目标模块、感知器、通信机制与协作机制、知识库、控制模块、推理模块、效应器以及类比模块等组成, 各个部分的作用和协作过程如下:
(1)感知模块依据目标模块中的任务时刻主动地接收网络环境中的信息,并对信息进行过滤、抽象、聚合, 现有搜索引擎中的Robot就能部分实现感知模块的功能。
(2)类比模块将感知模块所提取出来的符号及特征与知识库中的知识块进行模糊匹配,并用推理模块及知识库中的规则处理信息, 形成新的知识块。
(3)通信模块完成任务的发送、传递处理信息及与其他Agent的相互通信。
(4)协作模块使多个Agent 能够协同一致地完成工作, 在冲突发生时, 又能快速有效地协调冲突。
(5)目标模块中的初始任务由用户建立, 然后通过通信机制中动态地变化, 最终形成一个代表用户浏览意图的概念空间, 从而不断地适应用户的需求。
(6)控制模块是Agent 的核心, 它能综合和决策其他模块的信息, 针对目标模块中的任务列表, 在一定的信息条件与行为准则下, 利用感知的信息及知识库的知识块, 为任务求解做出有效的搜索过程、方法和问题状态的转移, 控制各模块的运行, 并将决策交由效应器实施。
(二)基于本体技术的语义检索
1.原理
传统信息检索主要通过条件检索和导航检索实现,而智能搜索引擎除了要应用以上两种检索方式外,更强调语义检索,即基于本体和用户的输入条件,完成语义推理过程,对用户检索的意图进行确定,进而以用户检索意图为检索方向进行查询,并向用户反馈的检索方式。可见基于本体技术的语义检索实际上就是用户通过用户界面,将搜索信息输入数据处理和语义推理模块,由其结合本体开发人员设计的本体知识库和数据仓库完成数据检索服务的过程,换言之就是利用本体技术将用户的搜索信息向搜索语义转化的过程。[9]
2.实现过程
基于本体技术的语义检索的实现,要保证语义检索系统包含以下三个结构:首先,数据服务器,在服务器中要包含以三元组形式存储的语义词典、知识库等领域知识集合体;其次,Web 业务层,在此结构中,既要包括可以将用户信息检索输入信息向本体概念形式转化,并依据JenaOWL 推理引擎完成推理分析,实现语义求解,完成数据服务器检索和反馈的信息检索引擎,又要包括为语义推理提供依据的推理引擎。再次,Web 终端,此结构的功能是与用户建立连接关系,通过JSP 技术对用户的搜索进行获取并将检索的结果向用户进行反馈。
-
八、智慧学习资源的智能分类技术
智慧学习资源的智能分类需要一个类别已标识的数据集来训练分类器,然后用训练好的分类器对未标识类别的资源进行分类。分类器的构造方法有许多种,基本上可以分为三大类:一类是基于统计的方法,如中心向量法、朴素贝叶斯、K 近邻(KNN)、回归模型、支持向量机(SVM)等方法;另一种是基于链接的方法,如人工神经网络;还有一种是基于规则的方法,如决策树、关联规则等。这些方法的主要区别在于规则获取的方式。
下面介绍几种智能分类技术中使用广泛的分类算法:
(一)支持向量机分类算法
支持向量机(Support Vector Machines,SVM)是在统计学习理论的基础上发展起来的一种机器学习方法,它基于结构风险最小化原理,将原始数据集合压缩到支持向量集合,学习得到分类决策函数。其基本思想是:根据结构风险最小化的原理,对一个给定的具有有限数量训练样本的学习任务,如何在高维空间中寻找一个超平面作为两类的分割,以保证最小的错误率。支持向量机在解决小样本、非线性及高维模式识别问题上表现出许多特有的优势,并在很多领域得到成功的应用[1]。
SVM 使用公式:

公式1
将向量d分成1(S>S0)或-1.其中:di,i=1,..., N是训练集向量;yi,i=1,...,N是相对应的类;K(d,di)是核心,是用来表示d度数的多项式:K(d,di)=(dTdi+1)T。αi 为每个样本对应的拉格朗日乘子。
若数据是线性可分的,SVM 为距离最小的两个类构造一个超平面
 。
。即存在向量 w 和标量b ,使得分类如下:

公式2
如果训练样本可以无差错地被划分,且每一类数据与超平面距离最近的向量与超平面之间的距离最大,则该超平面为最优超平面。求出向量 w 和标量b 后代入公式2,即可计算资源(向量d)的资源归属。
(二)朴素贝叶斯算法
朴素贝叶斯算法的思想基础是对于给出的待分类项,求解在此项出现的条件下各个类别出现的概率,哪个最大,就认为此待分类项属于哪个类别。它假设各个特征项是相互独立的,理论上讲,与其他分类器相比,贝叶斯分类器应该有最小的错误率,但是,对于现实而言,有时各个特征项独立条件并不严格成立,因此在特征项之间的联系比较紧密的情况下,该算法分类性能将会较差。即便如此,贝叶斯算法已在大型数据库的运用中表现出精度准,速度快的优势。贝叶斯分类算法具体过程如下:将待分类样本用X=(x1,x2...,xn)表示。设训练集为K个(C1,C2,...,Ck),每个类别Ci的先验概率为P(Ci)(i=1,2,3,...,k),其值为Ci类的样本数除以训练集总样本数。对于待分类样本,其属于C类的条件概率为P(X|Ci)。根据贝叶斯定理类别的后验概率P(C|Xi)为:

对于待分类资源被归为类别Ci时,必须满足条件:P(Ci|X)=max(P(Ci|X))。
(三)决策树分类法
决策树学习是一个树形结构,树上的每个非叶子节点代表一个测试特征每个分支表示测试的结果,每个叶子代表一个类标签。决策树分类器被广泛采用的原因是构建决策树不需要任何领域的知识,以树形式表达的知识易于被人理解,另外,决策树归纳法的分类步骤简单而迅速。除了分裂准则,另一个挑战是建立决策树时如何防止训练过度,要实现这个目标,必须对树剪枝。现有的构建决策树的方法,在分离类的过程中通过测试所有的属性值递归地划分测试集。最经典的算法是它的最初版本ID3,其具体步骤如下:检测所有的特征,选择信息增益最大的特征产生决策树结点,由该特征的不同取值建立分支,再对各分支的子集递归调用该方法建立决策树结点的分支,直到所有子集仅包含同一类别的数据为止,用最后得到决策树对新的样本进行分类。在计算熵的时,与朴素贝叶斯方法完全一样,都是使用频率估计的方法。但是每次选择特征,测试的特征与原有特征是无关的[2]。
(四) KNN算法
K最近邻(k-Nearest Neighbor,KNN)分类算法,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一。该方法的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。KNN算法中,所选择的邻居都是已经正确分类的对象。该方法在定类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。 KNN方法虽然从原理上也依赖于极限定理,但在类别决策时,只与极少量的相邻样本有关。由于KNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,KNN方法较其他方法更为适合。
-
九、智慧学习资源进化的控制技术
智慧学习环境下学习资源的形态更加多样化,资源本身更加智能化,能极大满足人们学习的需求。但是泛在学习中学习资源存在一定的不足,比如学习资源进化方向的控制和约束不足,资源呈现混乱生长状态;公共资源的群间共享特点,使资源质量良莠不齐,用户与资源之间出现了“信任危机”;学习资源更新速度缓慢,缺乏一定的进化动力。针对这些问题,从内容进化和关联进化两方面探讨了学习资源的进化控制。
(一)内容进化
内容进化是指学习资源通过开放的组织方式吸收多个用户参与内容的协同编辑,实现资源内容的快速更新和逐步完善,主要表现为资源内容版本的不断更迭和发展[1]。在此基础上提出了基于语义基因和社会信任模型技术的内容进化只能有序控制技术的总体框架,如图1。主要综合两方面的信息进行内容编辑的可信度计算,一方面进行语义相似度计算,另一方面计算用户的信任度。设定内容编辑可以被接受的可信度阈值,如果此次内容编辑的可信度超过阈值则自动接收此次内容的编辑结果,否则自动拒绝。这个模型具有较高的控制准确率,能够有效减轻资源管理者内容审核的负担。

图1 内容进化中的智能有序控制技术
(二)关联进化
关联进化是指学习资源在生长的过程中不断与其他资源实体建立语义关系的过程,是资源外部结构的完善与更新,资源的关系网会不断地丰富和扩展。学习资源之间关联计划中动态语义关联和聚合技术如图2所示。为了动态发现资源之间的各种语义关系,一方面根据资源的语义基因进行关系计算,需要用到WordNet语义词典,另一方面需要运用基于规则的推理技术,发现语义信息空间中不存在直接关系的资源间的关联。此外,为了发现没有明显语义关系但却具有潜在关联的资源关系,运用文本挖掘等数据挖掘技术进行改进,加入基于语义基因的语义约束,实现更高的关联效率和准确性。在发现各种资源关联的基础上,进一步应用基于规则的动态聚合技术将具有内在逻辑关系的多个资源个体自动聚合为特定形态的资源群------主题资源圈、有序知识群等[2]。动态语义关联技术的发展能够帮助学习对象快速搜索学习所需要的资源信息,起到“知识导航”的重要作用。

学习资源的进化以“发展、变化、适应”为核心,学习资源的发展不是静态的、直线发展,而是动态的、多元发展的,需要不断地适应学习环境的变化,并满足学习者学习的需求。动态建立挖掘和发展资源间的各种语义关系是实现资源进化的重要手段和目的,也应当注意到学习资源的计划是发生在学习资源的使用过程中的,进化发展应受到资源内在知识结构的制约,不能“随心所欲”的生长。
-
十、参考文献
[1] Al-Zoube M. E-learning on the Cloud[J]. International Arab Journal of e-techenology,2009,(2): 58-64.
[2] Ma H, Zheng Z, Ye F, et al. The Applied Research of Cloud Computing in the Construction of Collaborative Learning Platform under E-learning Environment[C]. System Science, Engineering Design and Manufacturing Information (ICSEM), 2010 International Conference on.IEEE,2010,1:190-192.
[3]杨现民,余胜泉. 学习资源语义特征自动提取研究[J]. 中国电化教育,2013,(11):74-80.
[4]楚京予,余本功,牛锋. MOOC平台下课程资源的组织模型及表示方案研究[J]. 电化教育研究,2015,(11):69-74.
[5]邵国平,余盛爱,郭莉. 语义Web对E-Learning中资源管理的促进[J].江苏广播电视大学学,2008,19(5):23-26.
[6]杨现民,余胜泉. 泛在学习环境下的学习资源进化模型构建[J].中国电化教育, 2011,(9):80-86.
[7]杨现民,余胜泉,张芳. 学习资源动态语义关联的设计与实现[J]. 中国电化教育,2013,(1):70-75.
[8]刘富逵,杨改学.基于WAP技术的移动学习系统应用[J].现代远程教育研究,2009,(5): 62-66.
[9]韩壮志,陈鹏,何强等.嵌入式系统显示界面的自适应显示方法[J].液晶与显示, 2010,(2):283-286.
[10]李晶.基于Agent的移动学习设备自适应模型的研究[J].中国远程教育,2008,(10): 71-72.
[11]李浩君,项静,华燕燕.基于ANFIS的移动学习资源自适应呈现模型研究,2013,(7):100-105.
[12]杨焱, 孙铁利, 邱春艳.个性化推荐技术的研究[J].信息工程大学学报, 2005,6(2).
[13]杨焱.基于项目聚类的协同过滤推荐算法的研究[D].东北师范大学, 2005,5.
[14]王永固, 邱飞岳, 赵建龙, 刘 晖. 基于协同过滤技术的学习资源个性化推荐研究*[J]. 远程教育杂志, 2011(3):66-67.
[15]许芳,徐国虎. 网络信息检索智能AGENT技术探讨[J]. 现代情报,2005,04:79-80+110.
[16]李晓红. 基于本体技术的语义检索及其语义相似度分析[J]. 电子技术与软件工程,2017,01:187.
[17]呼声波. 面向信息检索的智能分类方法研究[D].山东师范大学,2008.
[18]李敏. 基于规则和SVM的教育资源分类技术研究[D].新疆大学,2013.
[19] 杨现民. 泛在学习环境下的学习资源有序进化研究[J]. 电化教育研究,2015,(01):62-68+76.
[20] 杨现民,余胜泉. 学习元平台的语义技术架构及其应用[J]. 现代远程教育研究,2014,(01):89-99.
-
-
- 标签:
- 智慧
- 关键
- 学习资源
- 开发
- 专题
-
加入的知识群:

.jpg)

学习元评论 (0条)
聪明如你,不妨在这 发表你的看法与心得 ~